Our latest sponsorship update is from a team at the Institute of Engineering, in Kathmandu, Nepal. Click here for details on how to apply to the OpenBCI Discovery Program.
1. What are you making?
This project intends to build a system that is able to extract surface electromyography (sEMG) signals from inner speech and use them to interact with a remote workstation.
To fulfill the objectives of this project, the faint sEMG signals generated by the motion of articulatory muscles need to be detected, amplified, and transmitted wirelessly to a computing device. At the receiving station, the detected signals undergo preprocessing whereby prominent features of the subvocal speech are isolated and fed to a machine learning model. The model is trained extensively with a locally created dataset consisting of multiple recordings of sEMG signals obtained via internal articulation of selected English words.
For the initial phase of this project, the system will be tested by displaying real-time non-voiced English words on a monitor. More complex contactless and voiceless human-computer interactions will then be attempted by interacting with intelligent systems such as Cortana, Google Assistant, Siri, and Alexa to obtain user desired actions on smart phones and smart watches.

2. How are OpenBCI tools being applied?
Non-voiced speech causes minuscule motion in the tongue and selected facial muscles. The neuromuscular movement results in electrical activity which is captured using the dedicated hardware provided by OpenBCI.
Gold Cup Electrodes consisting of passive gold plated electrodes attached to ribbon cables are used to sample muscle activity. In order to increase electrical conductivity between the facial skin and the electrodes, a special Ten20 paste is applied. The electrodes are interfaced with the Cyton Biosensing Board which relays the EMG signals to a computer using the OpenBCI USB dongle.


3. Why is this research important?
This project is at the forefront of developing a novel human-machine interface. In the long-run, the concept explored in this research work will be applicable in the medical field as well as in the defense and security industry.
As an example, the outcome of our research can aid patients suffering from Amyotrophic Lateral Sclerosis (ALS), by providing them with an alternative mechanism of expressing themselves and interacting with the world around them. Similarly, intelligence agencies and military operations requiring silent and covert communication will benefit from the idea explored in this investigation.
4. System Architecture and Implementation Details
The architecture of the implemented system is depicted in figure 4, and a brief description of the various blocks involved in the design have been described.

- Electrode Placement: The placement of electrodes is based on the sensitivity of the facial muscles to the sEMG signals as shown in figure 5 and the table 1 below. The signals from the electrodes placed on the respective muscles were extracted and fed to the Cyton board. The electrode placement on the ear lobes is grounded.
| EMG Channel Number | Muscle Name |
| 1 | Levator Angulis Oris |
| 2 | Zygomaticus Minor |
| 3 | Zygomaticus Major |
| 4 | Orbicularis Oris |
| 5 | Omohyoid |
| 6 | Anterior Belly of Digastric |
| 7 | Mylohyoid |
| 8 | Platysma |

According to the above description, practical implementation by one of our researchers is shown in figures 6 and 7.
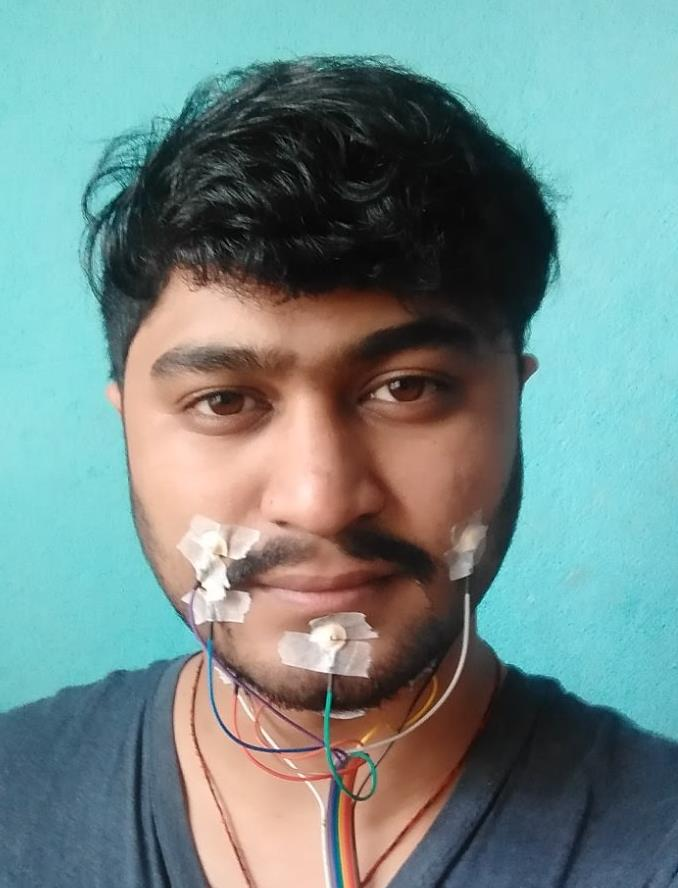
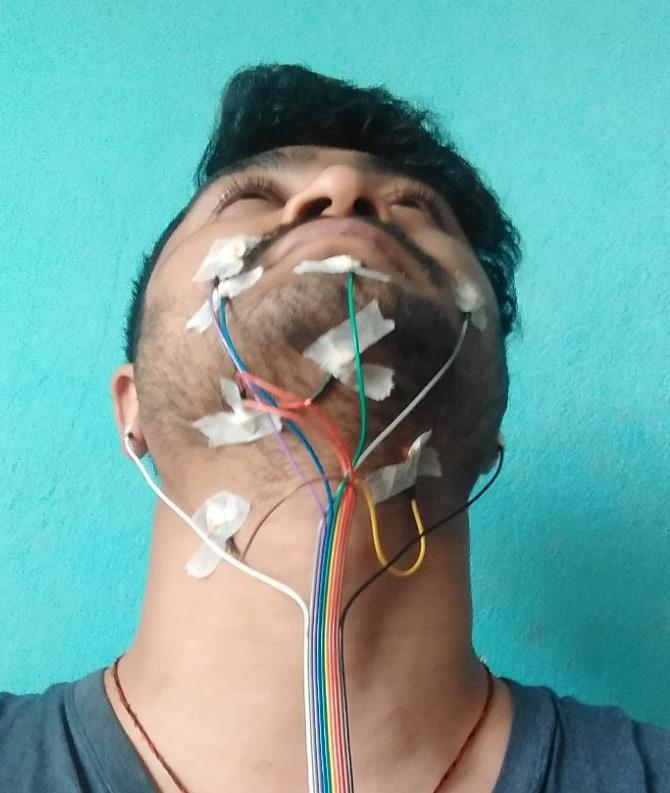


- Signal Amplification: The extracted analog EMG signal from the electrodes of all 8 channels was fed into respective differential amplifiers which eliminates any common mode noise and amplifies the signals according to the gain of the PGA (Programmable Gain Amplifier) which was set at 24 from the OpenBCI GUI.
- Signal Digitization: For ease of analysis, the analog EMG signal was converted into digital format. The differential output of the PGA was digitized using the 24 bit sigma-delta ADC within ADS1299. The signals are sampled at a frequency of 250 Hz.
- Serial Communication: The PIC micro-controller is the master device for ADS1299 and the Bluetooth module. It interfaces ADS1299 through SPI protocol and the Bluetooth module through UART. PIC micro-controller was responsible for configuration of ADS1299, which includes setting the gain of PGA, SPI data transmission rate, sampling rate of ADC and also controls the Bluetooth data transmission rate and connections. The PIC micro-controller was heavily involved in fetching digitized data from ADS1299 and sending the data to the Bluetooth module for wireless transmission.
- Wireless Communication: The wirelessly transmitted data from the Cyton board was received by the Bluetooth receiver embedded on the USB dongle. Then the USB-to-TTL converter on the USB dongle sent the data from the Bluetooth module to the computer through USB.
- Signal Processing: The digitized signal needed to be further processed before it was fed to a classifying neural network. The received signal may contain missing or erroneous data points and other inherent noises. Any faulty data points may cause the neural network to fail to generalize leading to a higher error in classification.
- Extraction of Signal Features: After the EMG signals were processed, they needed to be further translated to features that are the actual data contained in a multi-channel EMG signal. Since the EMG signal is very different from the speech signal, it was necessary to explore feature extraction methods that are suitable for EMG to text conversion. Temporal features such as Zero Crossing Rate, High Frequency Signals, Rectified High Frequency Signals, Frame Based Power and Double Nine Point Average were extracted. Spectral features were revealed via the Short Time Fourier Transform (STFT) by applying a sliding window mechanism on chunks of data.
- Machine Learning Model: The designed model has an input convolutional layer with 100 filters of size 1×3 that is followed by a max pooling layer with a pool size of 1×2. This convolutional layer and max-pooling layer was repeated once which was then followed by a fully connected layer with 100 nodes that was further connected to another fully connected layer with 10 nodes. The activation function that this network utilized at the convolutional and hidden layers was ReLU and at the output layer it was softmax. The model was optimized using Adam optimizer and was trained over 200 epochs with a batch size of 50 with the default learning rate of 0.001.

5. Dataset Description
The dataset was recorded from 4 male subjects of ages ranging from 22 to 24 years old with an average age being 23 years old. The subjects were directed to speak in two different modes: ‘Muscle Movement (MM)’ and ‘Mentally Rehearsed (MR)’. ‘Muscle Movement’ mode demands the users to utter words without making any sound, however permissible mouth movements while in ‘Mentally Rehearsed’ mode, neither any mouth movement nor any sound is permissible. The recording environment was kept the same for all the speakers. The dataset was formed through utterances of ten commonly used words; ‘Add’, ‘Call’, ‘Go’, ‘Later’, ‘Left’, ‘Reply’, ‘Right’, ‘Stop’, ‘Subtract’ and ‘You’, in two of the aforementioned modes. The word selection is based on the phonetic difference of the words.
| Mode | Sampling Rate (Hz) | Channels | Session Length (hh:mm:ss) | Speaker Count | Session Count |
| Muscle Movement | 250 | 8 | 1:00:01 | 4 | 6 |
| Mentally Rehearsed | 250 | 8 | 01:31:59 | 4 | 6 |
The distribution of the words (in both the recording modes) in the dataset can be visualized with the following figure.

Datasets are made openly available on Kaggle:
HCI EMG Dataset: DOI (10.34740/kaggle/dsv/2349993)
Nepali EMG Dataset-Version1: DOI (10.34740/kaggle/dsv/2973661)
Nepali EMG Dataset-Version2: DOI (10.34740/kaggle/dsv/2370654)
Nepali EMG Test Dataset: DOI (10.34740/kaggle/dsv/2562821)
6. Results
The raw signals captured from the selected facial muscles for utterance of the word “Call” in all the channels are as shown in the figure below.

Raw sEMG signals were filtered with appropriate digital bandpass filters to extract the temporal as well as spectral features which ultimately served as feature vectors for the designed neural network.


The performance of the convolutional neural network (CNN) model in terms of loss and accuracy is shown in figure 13.

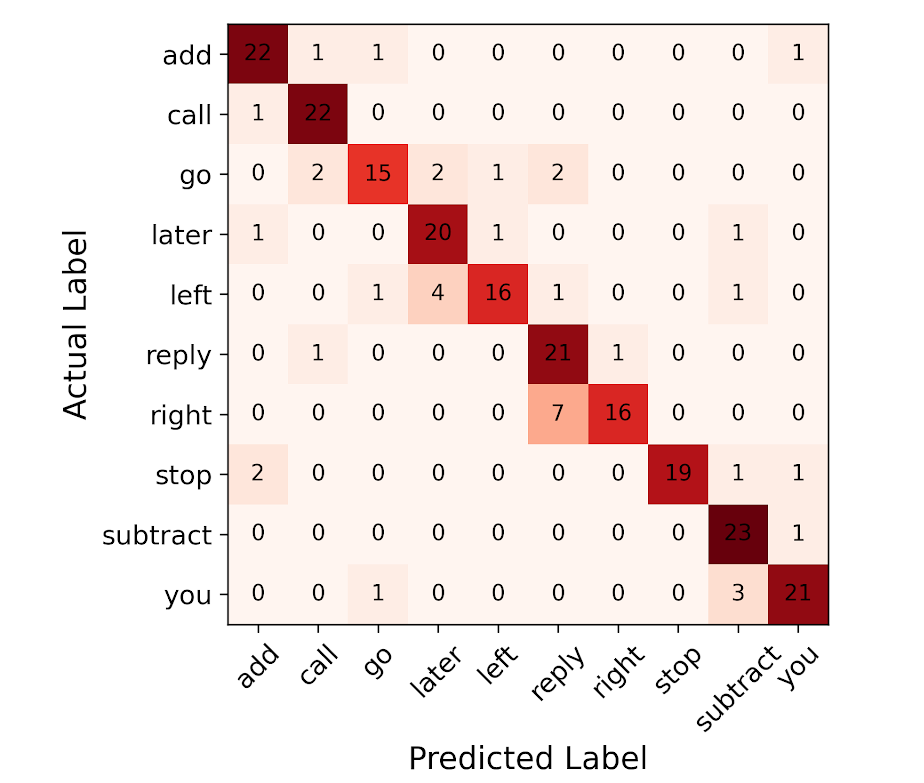
The confusion matrices are shown in figures 14 and 15. With both temporal and spectral features as input the predictions for the model in ‘Mentally Rehearsed’ mode were more accurate for words ‘add’, ‘call’, ‘subtract’, ‘stop’ and ‘you’ than those of remaining words.

7. Who is involved in this project?





Asst. Prof. Dinesh Baniya Kshatri: Principal investigator of the project and assistant professor in the department of Electronics and Computer Engineering at the Institute of Engineering, Thapthali Campus, Kathmandu, Nepal. He received his M.Sc. degree in Electrical Engineering from Stanford University, USA in 2011, M. Eng. degree in Electrical Engineering from Princeton University, USA in 2009, and the B.Sc. in Electrical and Computer Engineering from the University of Minnesota, USA in 2008.
Mr. Rabin Nepal: A fourth year student studying Electronics and Communication Engineering in the department of Electronics and Computer Engineering at the Institute of Engineering, Thapathali Campus, Kathmandu, Nepal.
Mr. Rhimesh Lwagun: A fourth year student studying Electronics and Communication Engineering in the department of Electronics and Computer Engineering at the Institute of Engineering, Thapathali Campus, Kathmandu, Nepal.
Mr. Sanjay Rijal: A fourth year student studying Electronics and Communication Engineering in the department of Electronics and Computer Engineering at the Institute of Engineering, Thapathali Campus, Kathmandu, Nepal.
Mr. Upendra Subedi: A fourth year student studying Electronics and Communication Engineering in the department of Electronics and Computer Engineering at the Institute of Engineering, Thapathali Campus, Kathmandu, Nepal.
Leave a Reply
You must be logged in to post a comment.