One major obstacle for wide application of BCI is the low signal-to-noise ratio. This can simply be resolved by boosting metabolism (higher signal intensity) and practicing focus (less drift of mind)…
plus some more sophisticated techniques, of course.
In this project, we hope to create a meta-learning (some machine learning technique) enabled model that learns from data generated on different users and allows fast adaptation in case of new user or new wearing conditions.
We plan to use the BCI electrode cap kit to collect data from a bunch of volunteers. We will then try a few numerical / machine learning techniques. This process will iterates a few times, until we have something good for demonstration.
After a reliable model is constructed, we will get a machine that can quickly and faithfully adapt to the each new use case with very few steps of adjustment. This will hopefully open the door to more large-scale applications of BCI in our daily life!
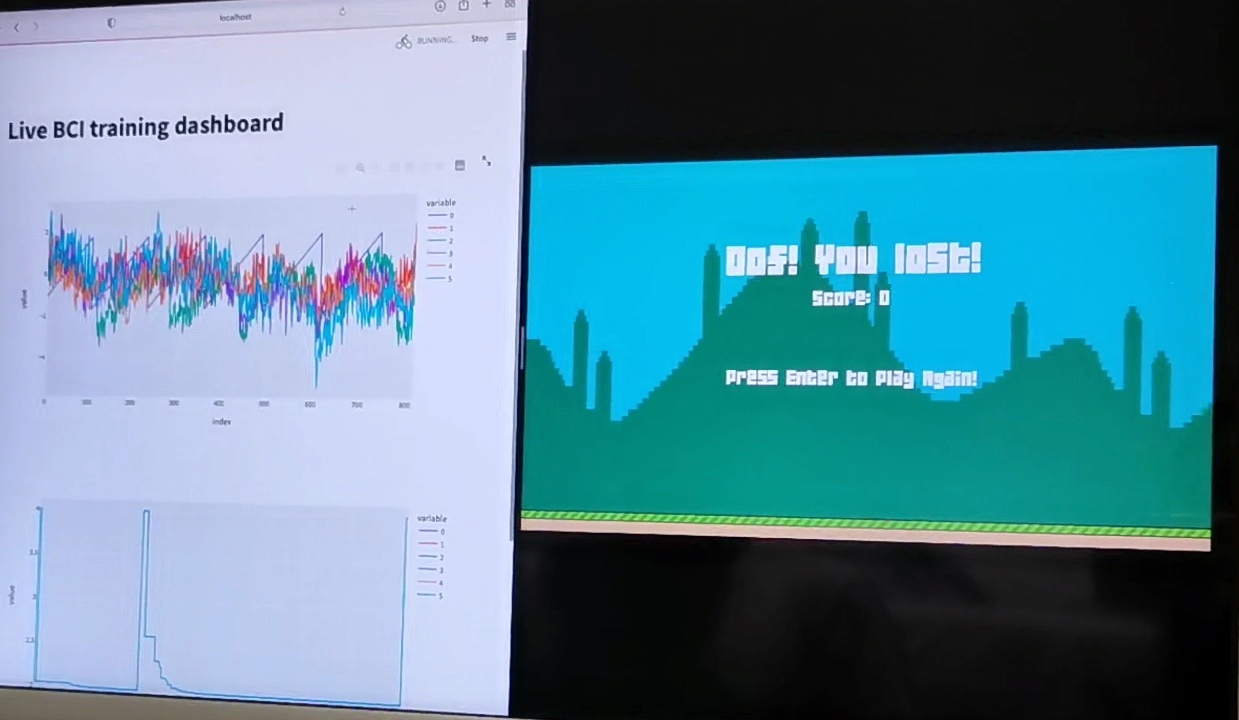
Moreover, be prepared to use our (will be open-sourced in the end) code for yourself! We have created a few game and visualization tools for the pipeline, so it will be pretty cool to try!
This project is primarily led by Beicheng (PhD in applied physics) and Sophie (MS in computational and mathematical engineering) from Stanford, with joint efforts from many passionate minds around them.
A longer and more serious intro to our plan
Our brain activity is bursty. It is impossible for the user to perfectly reproduce a pattern that the program is trained to recognize. Furthermore, the state of mind is constantly drifting and never the same as during training, which incurs more noise. This problem naturally calls for the application of self-attention, a widely used technique in machine learning that aims to focus on the right part of the input sequence. We plan to progress through a sequence of models, including convolutional neural networks, self-attention mechanisms and more sophisticated transformers. The main goal is to correctly pick out the good signal from a time sequence of input data, with the simplest model. For details, one can read https://arxiv.org/abs/1706.03762 for reference. We believe with a clever choice of model, we can overcome the problem introduced by the drift of mind and achieve much better results than using conventional methods e.g. hidden Markov models (which are not expressive enough).
There is also inevitable noise due to variation in wearing condition, e.g. contact location and connection quality, necessitating a different model every time of use. This is naturally a bilevel optimization problem that can be solved in the framework of meta-learning, where one intentionally trains the model to be fit for fast finetuning across multiple tasks (in this case, variation in device wearing). More specifically, we gather the data across different wearing conditions and sample the data into batches. The training process explicitly optimizes the model to perform well on all wearing conditions upon constrained finetuning. For details, one can read https://arxiv.org/abs/1703.03400 for reference. We believe a model that is designed to be adaptable across different conditions will greatly reduce the impact of the noise introduced by the variation in wearing conditions, thus making our model more suitable for practical usages.
Overall, we are very excited to apply our expertise to improve the interpretation of BCI data. We believe there are many drawbacks to the conventional methods and still great potentials achievable with improvements on software alone. By extracting more useful information from BCI data, our research can potentially enable many direct applications of BCI, e.g. typing, gaming and accessibility.
Contact
We’re based in Stanford, California, USA, and happy to work together!
If you’d like to join and discuss, feel free to contact Beicheng: [email protected]
Leave a Reply
You must be logged in to post a comment.